Picking up on the last article where we talked about the first few steps we take when exploring our data, the last step i.e Data cleaning is probably the most time and resource intensive step.
One of the first things you do when presented with a data sample (probably even before the Explore and Correlate step) is to split your dataset into Train and Test set. This is very important because you want to set aside some data to “validate” your approach and you don’t want your algorithm to “learn” about all the data points else you will have no idea how it will react when it is faced with a new so-far-unknown data point in the real world.
Random Sampling is one of the most common forms of splitting the dataset into test and train data and is as simple as taking a set percentage (typically 20%) of data randomly from the dataset and setting it aside. Random sampling works well when you have a large dataset with almost equal representation of different classes. But if your dataset is skewed i.e. it contains more samples for one class and less for the other then it may be important that your training set gets the right proportion of data from each class else you may fall prey to sample selection bias
Lets look at some examples to understand the need of maintaining the ratio of classes better:-
a) A very common example here is during electoral poll surveys they do not call random people but people are selected in such a fashion that the selected people are representative of the whole population. Therefore it is better if our training and test set also be a representative of the whole population so that the model is not biased.
b)Suppose you have a dataset comprising of heart beats per minute of a set of people. You want to predict the person’s lifespan on the basis of it. We know that age of a person plays an important factor in the number of heart beats per minute. Suppose the dataset comprises of 50% people in range of 18-30, 40% in range of 30-50 and 10% above age 50. As you can see the data set is skewed and the representation of different classes (age in this example) is 50:40:10 . But the distribution of the age range in this dataset represents the distribution of the age of the actual population. A model trained using the training set created by Random Sampling may not be in the ratio of 50:40:10 and hence may not give us the most accurate results.
Stratified random sampling involves first dividing a population into subpopulations and then applying random sampling methods to each subpopulation to form a test group.
It splits the dataset in such a fashion that train and test set will maintain the ratio of the samples in the original dataset. All we need to do is pass stratified sampling the column, whose proportion you want to maintain in train and test.
Next lets see some code taking SPAM classification as an example.
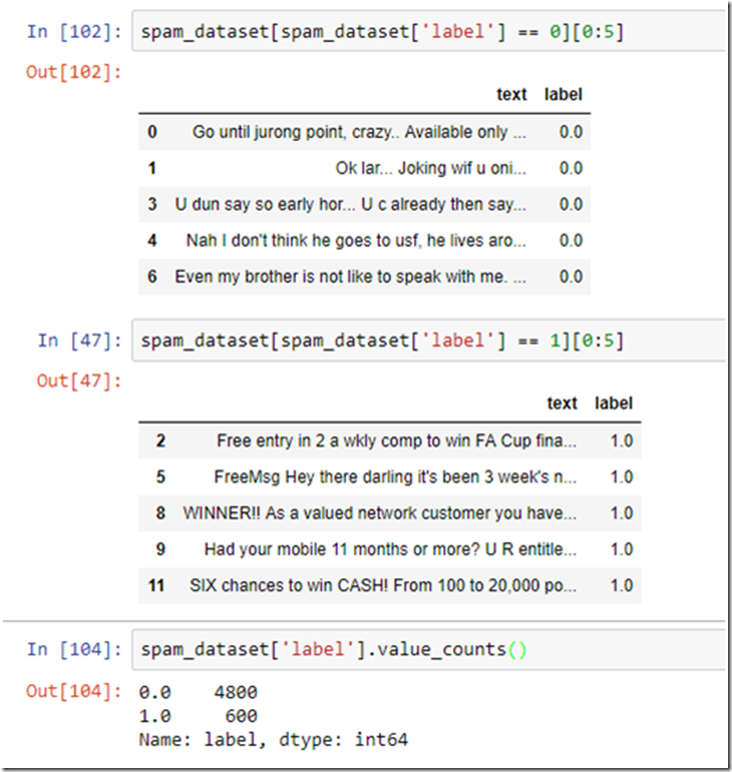
The dataset contains two columns text and label. The text column contains the message and the label column contains 0 or 1 indicating whether the message is normal or spam.
As you can see the dataset contains 4800 normal or non-spam messages and 600 spam messages. The ratio is 8:1. Lets split the data using random sampling as well as stratified random sampling and see the representation of spam and not spam in the training set.
Division using Random Sampling:-
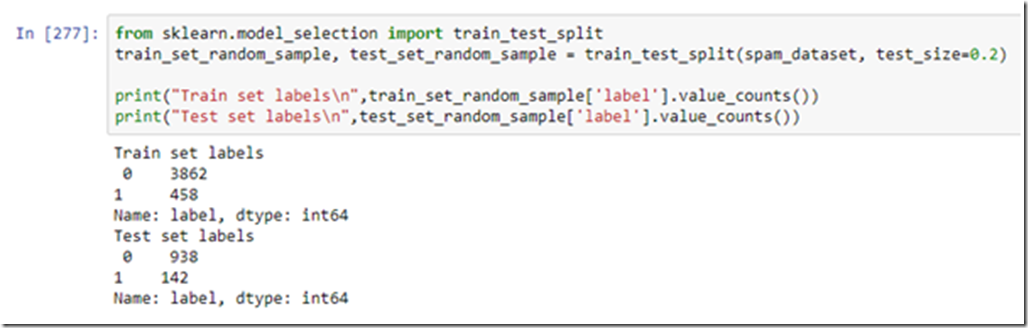
*Note that the train_test_split method randomizes the data before splitting (hence the name random sampling)
You can see the ratio of 8:1 is not maintained in random sampling. If the ratio had been maintained we would have the following:-
| Train | Test | |
| Non-Spam | 3840 messages | 960 messages |
| Spam | 480 messages | 120 messages |
Division using Stratified Sampling:-
a) Using train_test_split
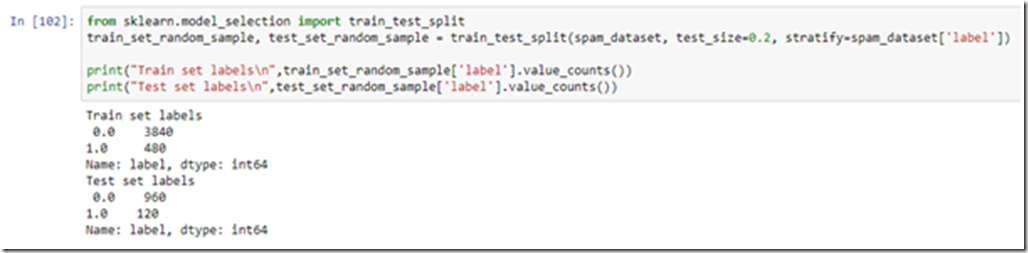
Basically we used the same train_test_split method and simply set the ‘stratify’ parameter to the column whose ratio you wish to maintain.
We got a perfect 8:1 representation of not spam and spam classes
b)Using StratifiedShuffleSplit
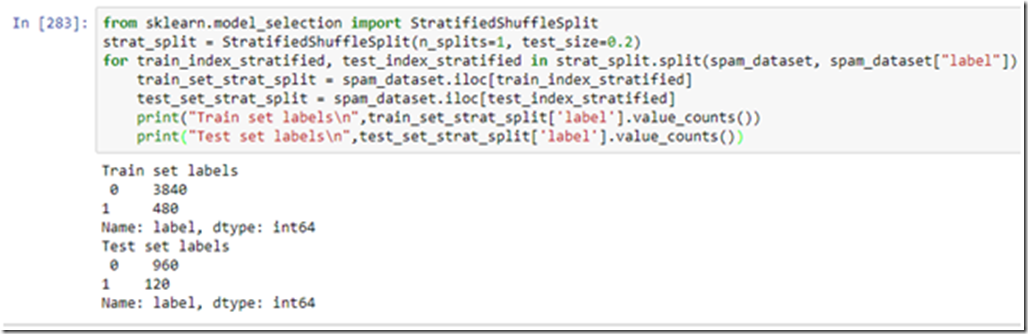
Here we specify the column, whose ratio we wish to maintain. The “shuffle” in the stratified shuffle split ensures the dataset is shuffled before the split so that we don’t get the sequential data.
We got a perfect 8:1 representation of not spam and spam classes
Overall Stratified sampling will almost always give more accurate results since it reduces sampling error and ensures greater level of representation . However it may not always be possible to go for stratified sampling
a) Sometimes it may not be possible to fit a datapoint into a one and only one sub-population group. Classification like gender, age etc are easy but things can get into the “grey” areas when we get into classifications like languages, caste, race etc
b) Collection of data may take more time as we need to ensure data about the sub-population group is collected alongside (which may not even be known to begin with)
Now that we have split up our data into test and training set, next we will look into some pre-processing activities we do to clean up and prepare the data!
Until Next Time!
Keep Coding!
Team Cennest!